Marunomicon
This book is a collection of knowledge pertaining to all parts of Maru, including key concepts, usage (someday), architecture, background knowledge, and more.
Note: This is a work in progress. None of these designs should be considered final
Introduction
Before diving into the details of Maru, let's first get an idea of the kind of problem Maru tries to solve.
The problem Maru solves
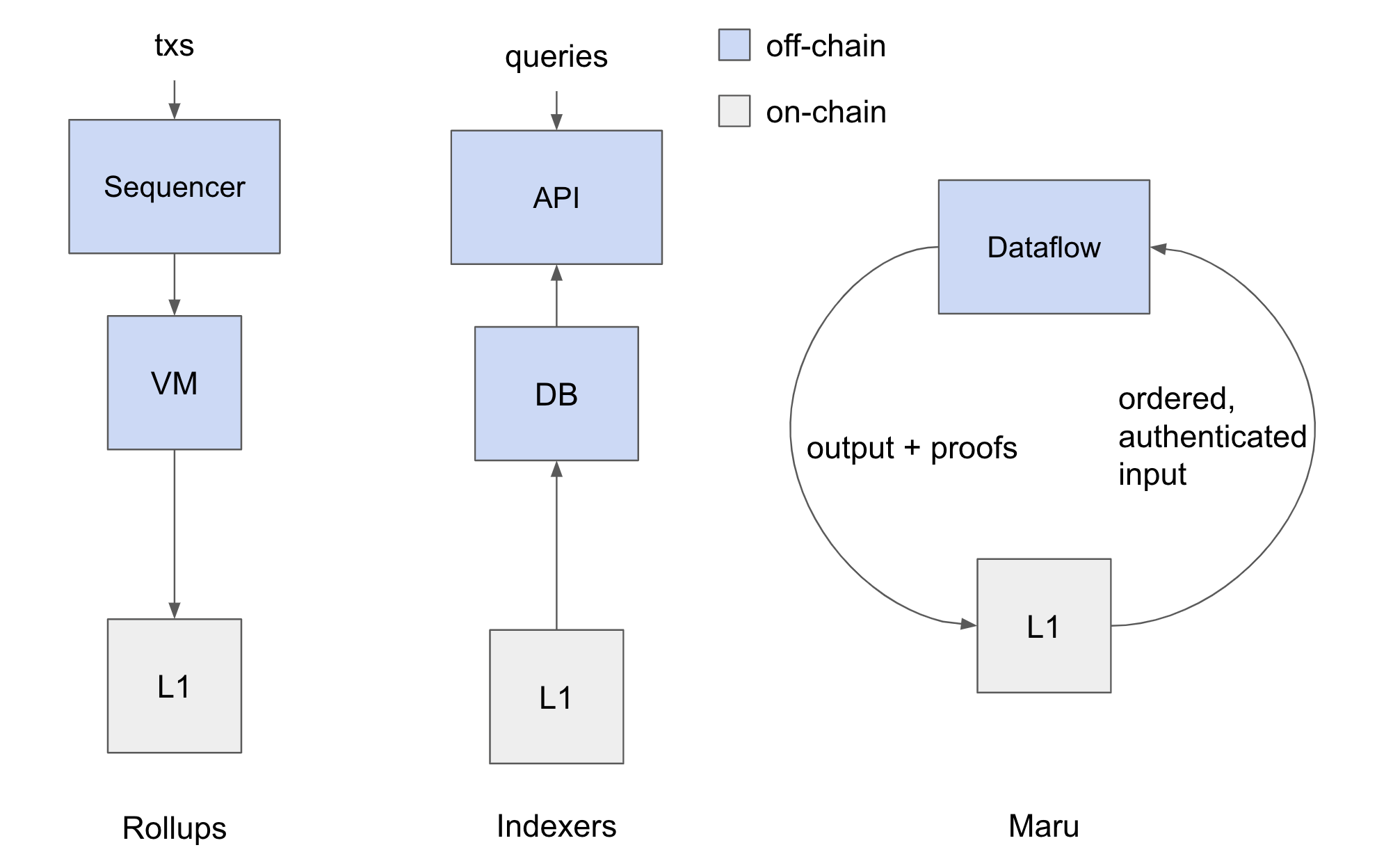
Blockchains are highly resource-constrained environments, so there are large inherent constraints on what developers can do on-chain. Thus, people have developed infrastructure that does stuff off-chain, but in a manner with security guarantees as close to those of L1 as possible:
- Rollups, which take off-chain data, "sequence" it into batches of transactions, execute them to produce state deltas, and periodically settle those state deltas in batches. This allows them to execute many more transactions than L1 can. There are two kinds of rollups:
- Optimistic rollups (OR) have to be "re-executable" on L1, so you can't perform a computation in an OR that's infeasible to perform on L1. By "infeasible", we mean actually infeasible (e.g. uses above max gas or different programming model incompatible with that of the L1) - "expensive" operations that are feasible to perform on L1 are ok.
- ZK Rollups (ZKR) don't have to be "re-executable" on L1 - they are free to use whatever programming model, so long as the proof is cheap enough to verify periodically on L1. Almost every ZKR in production today is focused only on payments, not "general" computation. That said, we're beginning to see "general" ZKRs come online (e.g StarkNet).
- Indexers, which take on-chain data, perform some computation to get the data into a queryable form (i.e. an index), and make that index available to code that exists off-chain (e.g. webapps, backend APIs, etc). Building indexes requires scanning over massive amounts of data, which is not feasible on-chain.
- Oracles, which take off-chain data, "verify" it against the source, and settle "on-chain" after the verification process. This allows people to query data from REST APIs and settle it on-chain.
While each of the solutions differ in trust assumptions and how much security they retain from L1, they share one common goal - do as much work as possible off-chain while retaining as much security as possible. In doing so, however, they lose a crucial property that exists on-chain - secure composability. Off-chain indices secured by "fishermen" and "optimistic challenge periods" are not composable. A smart contract on one rollup can't call a smart contract on another rollup without a state bridge. One oracle secured by a "multisig" can't be fed into another without a loss of security or stronger trust assumptions at every step of composition (does the smart contract need to verify the multisig for every oracle? Is it sufficient to do so only at the end? etc).
This is a problem if we want to actually build a "new web". The reason "web2" was so successful was because people could stitch APIs together into complex applications, but, at the moment, the only secure composability we have is in smart contracts. This is what Maru provides in a most general sense - scalable, secure, and composabile off-chain infrastructure.
| solution | functionality | finality / data consistency | security | scalability | composability |
|---|---|---|---|---|---|
| oracles | 'verify' off-chain data and make it queryable on-chain | strong (trust oracle provider to provide consistent data) | multisig | depends | introduces stronger trust assumptions at each layer |
| indexers | index on-chain data and make it queryable off-chain | weak (must wait for fishermen to resolve challenges) | fraud proof | depends | indices can't build atop other indices |
| optimistic rollup | do expensive stuff off-chain and batch-settle to L1 | weak (must wait for challenge period) | fraud proof | rollup txs must fit in L1 gas limit | cannot compose proof instances |
| zkVM rollup | do expensive stuff off-chain and batch-settle to L1 | strong (immediate finality on L1) | ZKP | sequential execution - O(N) recursive proofs - O(1) | cannot compose proof instances |
| Maru | all of the above | strong (immediate finality on L1) | ZKP | parallel execution - O(1) recursive proofs - O(1) | stream operators fully composable and only need to be executed/proven once |
How Maru solves that problem
It's become quite clear that L1s are best used for data availability and verification, and that everything else should happen off-chain - it's a place we settle data. Rollups and Oracles package off-chain data and post it on-chain. Indexers package on-chain data and post it off-chain. Maru completes the circle - it packages on-chain data, processes it off-chain, packages that off-chain data, and posts it back on-chain.
How? Using ZKPs. A ZKP allows us to prove "computational integrity" (CI) - that is, prove that, given an input A and a program P, a claimed output B is, in fact, the correct output of P when you give it A as input. In other words, if we trust the input, we can trust the output. We trust the consensus of L1s, and therefore we trust the input. The block hash is a digest of all data in the blockchain, and we can use it to build a succinct proof of CI - all we need to verify it is the current block hash, no matter how big the input is. And if we settle the proof on the same blockchain we took the input from, we have the block hash, and we can post the output data only if the proof verification succeeds. Or, we can settle the proof on a different blockchain, in which case Maru acts like a bridge (though with some extra trust assumptions).
However, we're not limited to a single program. If program P1 takes as input A and outputs B, and P2 takes as input B and outputs C, we can make CI proofs for P1 (A -> B) and P2 (B -> C). Then we can "merge" the two proofs together and make a single proof for both (A -> C) via a "recursive proof". Since we have a proof for each step, there's no loss in security from one step of composition to the next, unlike a "multisig" or "optimistic challenge period". And Maru is designed to do this at massive scale without consensus.
It's also worth mentioning that Maru can pull data from any ordered, authenticated source. It's not limited to blockchains - it can be an oracle, a signed data feed from a 'trustworthy' organization, or something else. Each data source will come with different trust assumptions, and it's ultimately up to the developer to evaluate them on a case-by-case basis.
How is this different from...
a 'general purpose' zkVM rollup?
A zkVM rollup must order (i.e. sequence) transactions on its own. Maru explicitly relies on the data source for that. Additionally, Maru's programming model (composable operators) allows parallel execution and composability without bridges. In contrast, while a zkVM rollup could give different applications their own VM, composability between those applications requires a 'bridge'. One can actually think of Maru as a parallel zkVM rollup where each "application domain" has separate state and the data dependency graph is specified at compile-time.
an indexer?
An indexer only builds indices - that is, they take data from chain, package it in a queryable form, and make it available. Maru is a general compute platform, not an indexer, though it could very well act as one.
an oracle?
An oracle only takes data from off-chain and posts it on-chain, whereas Maru also pulls data from off-chain and makes it usable on-chain. Oracles also can't "mix" off-chain data with on-chain data through computation before settling to L1 without complicated trust assumptions, while Maru can. That said, since Maru only requires data sources be "ordered" and "authenticated", Maru can use oracles as data sources, and Maru can pull from the same data sources that they do.
Programming Model
The first order of business is Maru's programming model. As a verifiable streaming computation platform, Maru is quite powerful and can do a great many things. However, it operates under a different computational model than you're probably used to - it's quite different from the EVM, an API, or a database. To help you build a conceptual framework for Maru's programming model, let's sketch out some key terms, their roles, and how they interact:
| Component | Role |
|---|---|
| Record | A single, small-ish element of arbitrary data. |
| Collection | An unordered set of records that keeps track of how many copies of each record are in the set. Analogous to a "multiset" or a "bag". You can think of it like a set of (record, count) pairs. |
| Delta | An incremental update to a collection, consisting of a record and difference in the number of instances of that record. e.g. (data, 1) means "insert 1 instance of data to the collection", while (data, -1) means "delete 1 instance of data from the collection". |
| Stream | An ordered stream of deltas, where each delta has a logical timestamp T. Streams are periodically accumulated into collections (i.e. "adding" together all of the deltas). |
| Operator | A single compute element that takes any number of input streams and produces any number of output streams. Specifically, it's a function that takes in one or more input deltas and outputs one or more corresponding deltas to be applied to the output. Operators are highly composable. |
| Source | A stream that comes from an external data source - it is not the output of any operator. |
| Sink | A stream that is not the input of any operator - instead, it's pushed to a user / external consumer. |
| Dataflow | A structured network of operators - the outputs of one can serve as inputs for another. The result is something resembling a directed-acyclic graph (DAG) of operators. |
Collections of Records vs Streams of deltas
Maru state is made up of Collections of Records. Since collections can get quite large and are updated frequently, instead of storing the collections and performing updates directly, instead we process Streams of deltas - tiny incremental changes to state. Then, we periodically "combine" or "fold" all of the deltas together, reconstruct a "snapshot" of the underlying collection, and store it somewhere cheap.
This is not only more efficient to process but also more efficient to prove, since most streaming computations can be broken down into many tiny pieces. Not only are deltas cheap to prove, but they can be proven in parallel.
Operators
If you're a developer, you've propably seen JavaScript code that does something like this:
let res = collection
.map(x => /* return a transformation of x */)
.filter(x => /* return a boolean */)
.reduce((acc, x) => /* return a new accumulator given x*/)
// etc
Conceptually, operators are a generalization of the map, filter, reduce methods in JavaScript - an iterator over a collection is fed into the operator, and it processes each element, spitting the result into a new output iterator.
Unlike JavaScript, you can write your own operators - you're not limited to map, filter, reduce, or some other operator that's already implemented in the langauge. More importantly, also unlike JavaScript, the "streams" aren't Collections of Records, they're Streams of deltas. That means the following:
Your operator isn't answering the question "given an input collection, what's the output collection?", it's answering the question "given a change to the input collection, what corresponding changes do we need to make to the output collection?"
This might be the trickiest part of Maru's programming model to grok, and it comes more naturally the more you think about it. That said, here are some helpful thought-bites to help you wrap your head around it:
mapis exactly the same with deltas as it is with collections.filteris too.- To implement a
sumincrementally, multiply therecordby itscount- if the count is negative, we'll subtract the record's value from the sum, which is exactly what we want to do. - Most Stateful (Min, Sort, Join, etc) operators can be implemented in a way that doesn't require reconstructing the underlying collection - just having access to previous deltas is sufficient.
- To read more about it, see the background knowledge section.
Dataflow
One of Maru's greatest strengths is the fact that operators are composable - the output of one can feed into the input for another. Furthermore, Operators needn't be unary - they can have any number of inputs and/or outputs. And since every operator's output is proven, anyone can trustlessly compose one operator off of another, encouraging work-sharing.
If we were to visualize the structure of the operators feeding one into another, we'd end up with something looking like this:
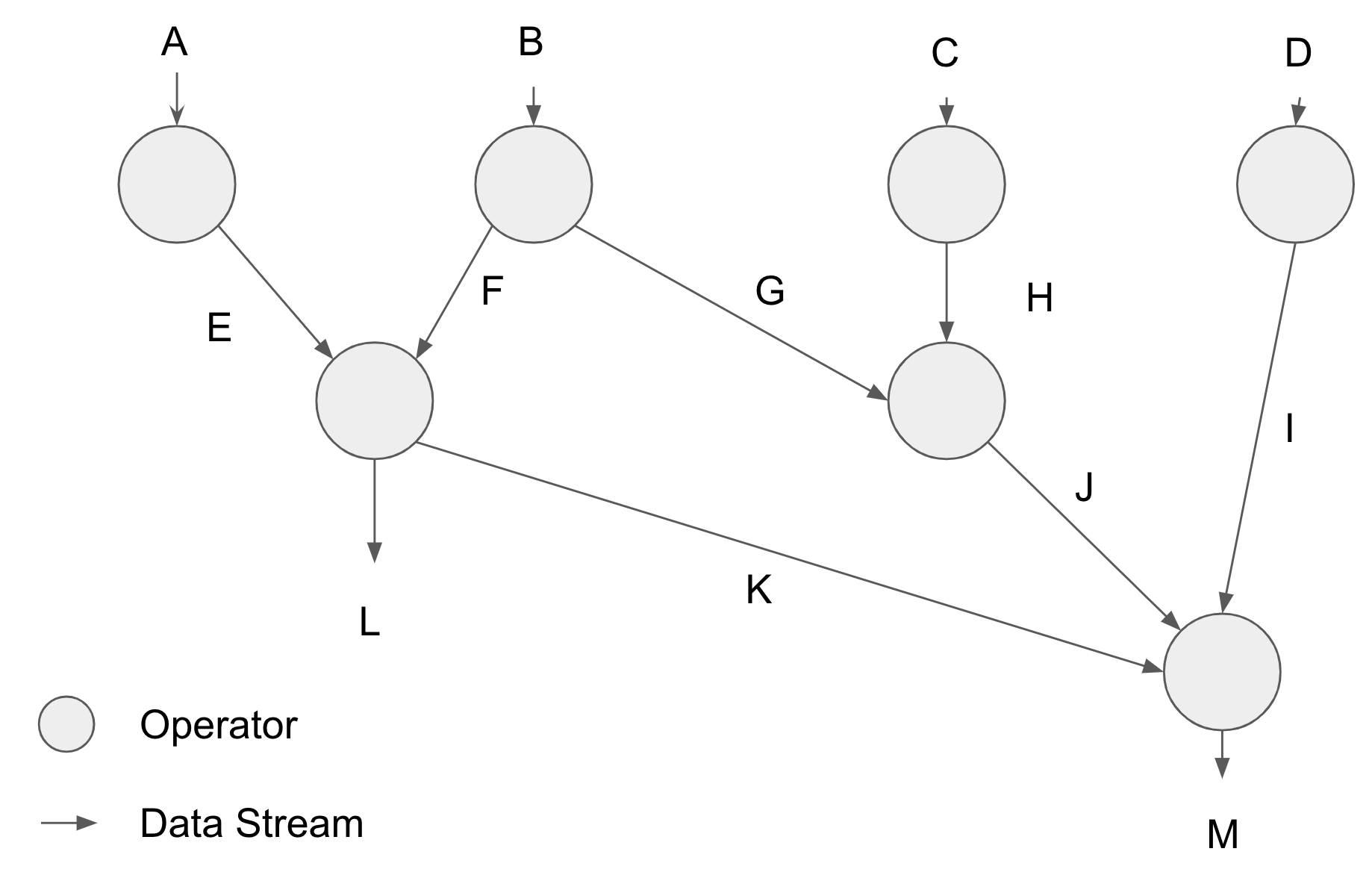
The real power of composability here isn't that developers don't need to implement their entire data pipeline from scratch, it's that, for each delta, each operator only needs to be executed and proven once, no matter how many downstream operators use the output. In this example, streams L, K, M, J, G, and F all use work of the operator at B, and thus the cost of it can be spread evenly across them all.
But that's not even the best part - stream composition also incentivizes applications to co-optimize their applications, extracting out common sub-operations and removing all redundant work. This incentive brings together teams working on separate products to contribute to Maru. In turn, Maru has more resources it can put into processing more data, leading to more co-optimization, leading to more data. It's a virtuous cycle that encourages a strong community to develop around making sure everyone's computation is fast, reliable, and cheap. You can read more about how this works in how-maru-works.
How Maru Works
This section is a deep-dive into the nitty-gritty details of Maru. If you want a more high-level description, see programming model.
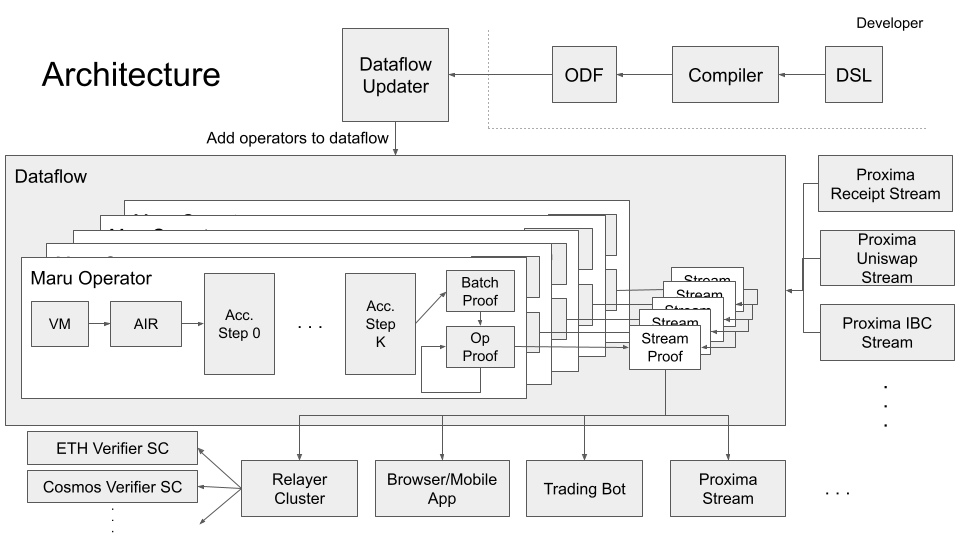
Architecture
In this chapter, we will list the high-level "modules" of Maru and briefly explain their purpose and how they fit together. Subsequent chapters will dive deeper into their respective components.
| Module | Role |
|---|---|
| Runtime | The VM for processing individual deltas and the STARK-prover for that VM. Feeds into Proof Pipeline under a developer-chosen Accumulation Strategy. |
| Proof Pipeline | An embarrassingly-parallel pipeline for recursively accumulating many thousands of proofs per second. |
| Arrangements | Manner in which a stream of deltas should be sorted / indexed. |
| Operator | An abstraction representing a single "compute element" in the dataflow - consists of runtime bytecode and a recursion strategy |
| Dataflow | Distributed system that moves deltas between operators and executes the proof pipeline. |
| Relayer Network | Network of nodes that subscribe to output stream(s) of the dataflow, compress the proofs, and submit them to the blockchain |
| Verifier Smart Contract | A smart contract that verifies the final proofs generated by the relayer network. |
At a high level, the architecture looks something like this:
Dataflow
The "dataflow" is the underlying implementation of Maru operators and their composition. It can be thought of as a "DAG of operators" that is responsible for allocating work to operators and moving deltas from their origin to the operators that need them.
The centralized version of Maru builds atop differential Dataflow, itself a wrapper around Timely Dataflow. Maru simply extends the operator definitions in differential Dataflow with our prover pipeline and executes them through our runtime. See the dataflow chapter for details on how exactly we do this.
Operators
Operators are units of stream-handling logic specified by a developer. A developer implements their operator logic using a domain-specific-language (DSL). The compiler for this DSL outputs what is called an "operator definition", which includes the bytecode(s) for the operator(s) logic and a descriptor file that explains how to connect them together and "graft" them onto the global dataflow. You can read more about the DSL here.
Runtime
The runtime module consists of Aincrad, Maru's STARK-AIR that proves computational integrity (i.e. correctness) of an execution trace from the Aincrad Runner, our VM. The VM runs bytecode supplied to the dataflow via an Operator Definition File (ODF), which is discussed in adding operators to the dataflow.
Aincrad requires that all deltas needed in the computation be given to it up-front. This means that the dataflow is responsible for providing any historical deltas that need to be considered in order to produce the output delta(s), and therefore they must be defined up-front. Oftentimes this requires using a recursion strategy to arrange historical deltas in a way where this is feasible.
If you've ever written programs on Solana's runtime (Sealevel), this may seem quite familiar. Like Sealevel, Aincrad requires all accounts (state) to be provided as an explicit input at the beginning of execution. Unlike Sealevel, however, Aincrad take deltas as input instead of states.
Read more about the runtime at runtime.md
Proof Pipeline
The proof pipeline is the how Maru horizontally-scales. In the past two years, recursive SNARK performance has improved drastically. In particular, Plonky2 recursion takes ~180ms on my Macbook from 2019 for a reasonably-sized circuit, which makes it feasible to have 10, 20, even 50 layers of recursion, allowing Maru's throughput to scale linearly with the number of CPUs we can throw at it. And once Maru is decentralized, the amount CPUs going into Maru will be massive.
How does efficient proof recursion enable parallel proof generation? It allows us to execute a sequential computation but prove it in parallel. This is one of the core ideas behind Mina, and in Maru we utilize plonky2 to take this idea to its extreme.
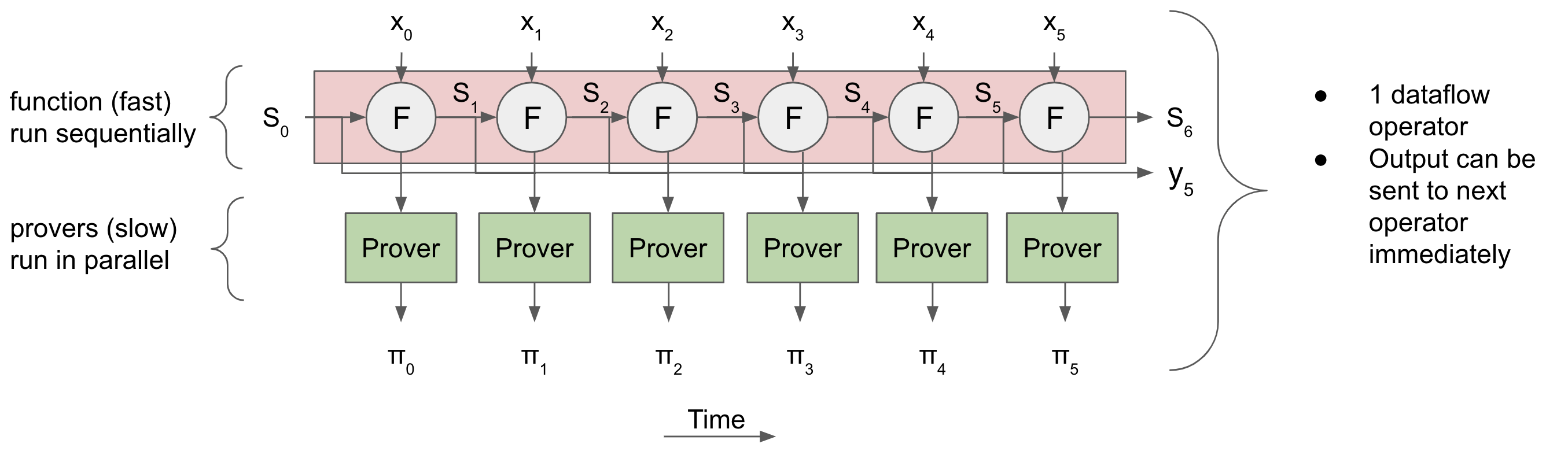
Then, we can use recursion to "merge" or "accumulate" all of the proofs together in a tree-like fashion. In this "accumulation tree", each layer only depends on the layer "below" it, so we can pipeline several batches of proof accumulation - At the same time, the first batch can be accumulated in the first layer of the tree, the second batch of STARK proofs can be generated, and the third batch of deltas can be processed.
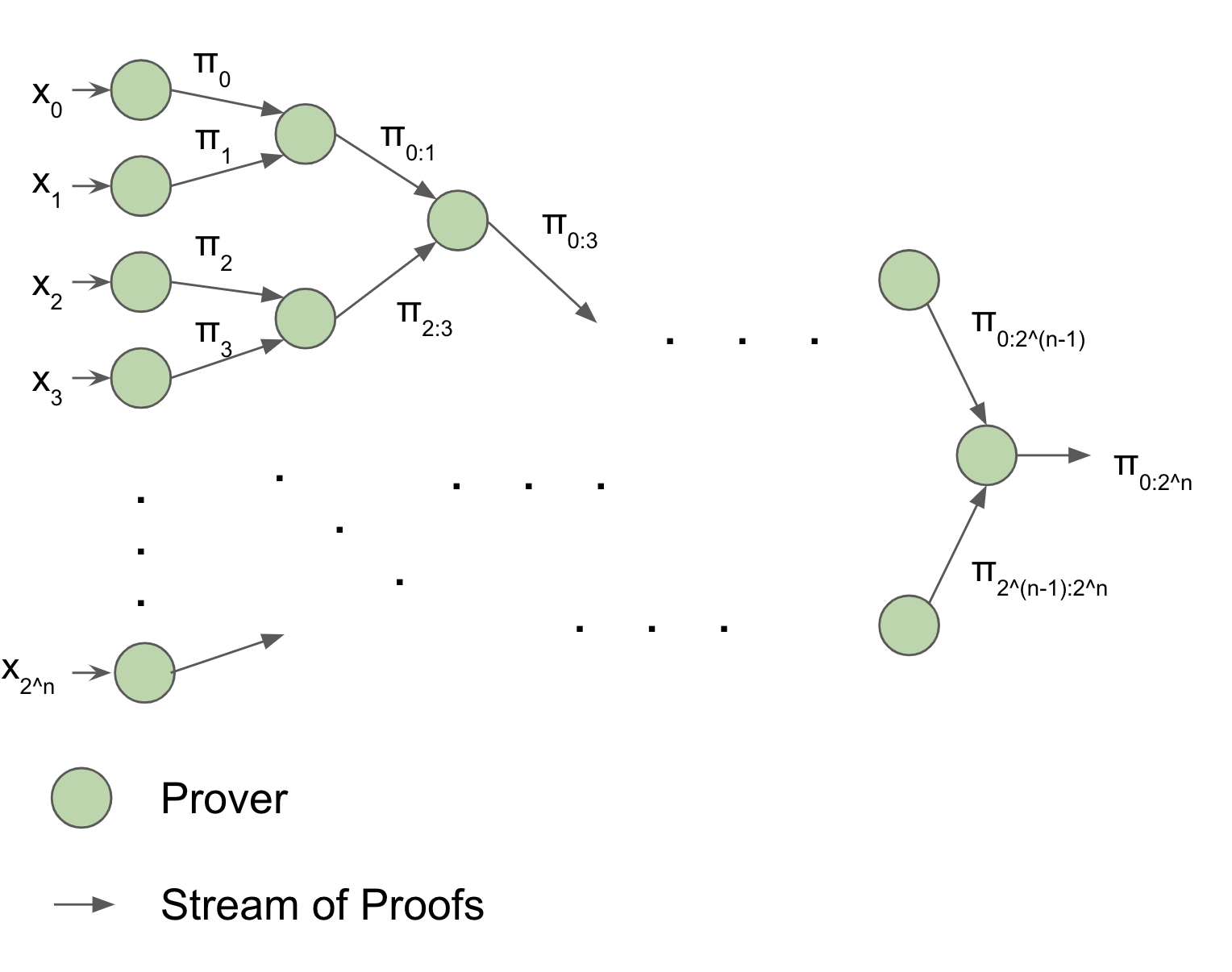
Everything is at full-utilization. And if we want to accumulate bigger batches, we can just add a layer to the tree. Then, as long as we have enough CPUs, throughput will double while latency will only increase by a fraction of a second. And at the end, the verifier only has to verify a single proof.
How does this fit into everything else? This proof accumulation tree corresponds to a single batch of deltas fed into a single operator. We can add more layers to prove a sequence of batches in parallel, and we can add even more layers to prove a sequence of batches for a sequence of operators in parallel, so the pipeline ends up looking something what's shown in the architecture diagram above (duplicated here to save your working memory):
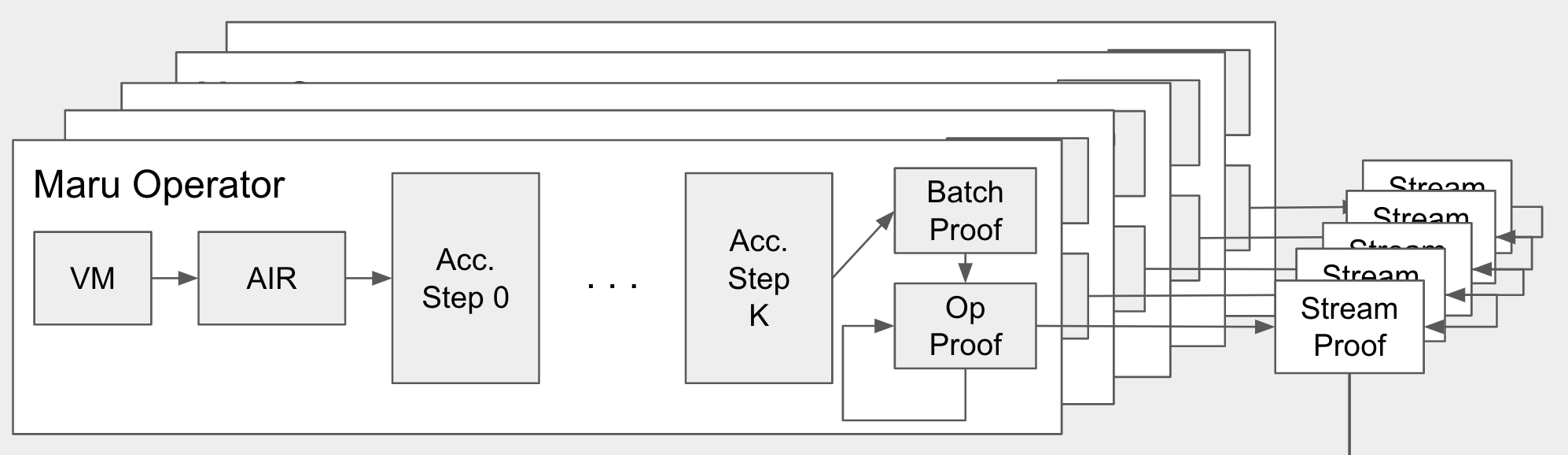
Arrangements
Arrangements are indexed versions of a stream. These are needed because many efficient algorithms require random access to a stream's historical deltas. For example, min and max requires access to historical deltas, and in particular it needs to keep track of the current minimum or maximum of the records. This effectively amounts to a sharded "key-value store interface" for a collection. Differential Dataflow implements them as basic tries.
In Maru, however, it's not enough to simply index the streams, since, now that we're doing "random access" from a collection, we need membership proofs. Unfortunately, multiset hashes don't give us membership proofs, so we maintain arrangements as Merkle tries. We then use a special "arrangement STARK" to prove correctness of the updates to the arrangement against the stream's running multiset hash. This merkle root is elided away during proof accumulation, so the verifier still only needs the block hash to verify the proof. You can read more about how exactly we do this here.
Dataflow
Differential Dataflow is already a well-defined computational model, and there already exists a robust distributed implementation. Thus we can implement Maru operators "abstractly" as a composition of multiple differential dataflow operators.
Even though the existing implementation relies upon a centralized scheduler, a decentralized implementation can be made of the same computational model, upon which we can run Maru operators just the same as in the centralized version.
Aside: You might ask the question, 'why not just make it decentralized from the beginning"? Because proving complex streaming operations is hard enough, not to mention the fact that we need to build a business. One problem at a time, anon.
In this article, we refer to Multiset Hashes as "MSH". See the chapter about them in background-knowledge for more information before reading this article.
Maru Operator Definition
A Maru operator is the combination of a set of input maru streams, output maru streams, some form of logic that, given a delta, produces another delta, and an optional arrangement (In Maru's initial release, arrangements will not be supported).
A "maru stream" is defined as a group of three independent differential dataflow streams:
- Delta stream
- stream of differential dataflow "deltas".
- cumulative MSH stream
- each element is the cumulative multiset hash of every delta that came "before" that element's timestamp.
- cumulative proof stream
- Proofs take the cumulative multiset hash of both the previous operator's input and the prevoius operator's output as public input, and prove that the collection committed to by the output MSH is correct given the collection committed to by the input MSH
Unary Operator Implementation
A unary operator's execution goes like this:
- for each input delta, run the operator's logic to determine the corresponding set of output deltas. Emit the execution trace for the logic.
- concurrently:
- a. generate / accumulate proofs:
- i. for each execution trace, generate a STARK-AIR proof that the logic was executed correctly.
- ii. recursively accumulate each of these proofs into a single "cumulative operator proof", and, in doing so, "build up" the "expected" cumulative multiset hash in the proofs
- iii. recursively accumulate this "cumulative operator proof" with that of the previous operator's cumulative stream proofs, checking that the input MSH for the current operator and the output MSH for the previous operator match. The result is the output cumulative proof stream.
- b. update output's cumulative multiset hash with new deltas produced by the operator's logic.
- a. generate / accumulate proofs:
- output the output delta stream, cumulative MSH stream, and cumulative proof stream.
We can implement this using differential dataflow primitives using the configuration shown in the diagram below.
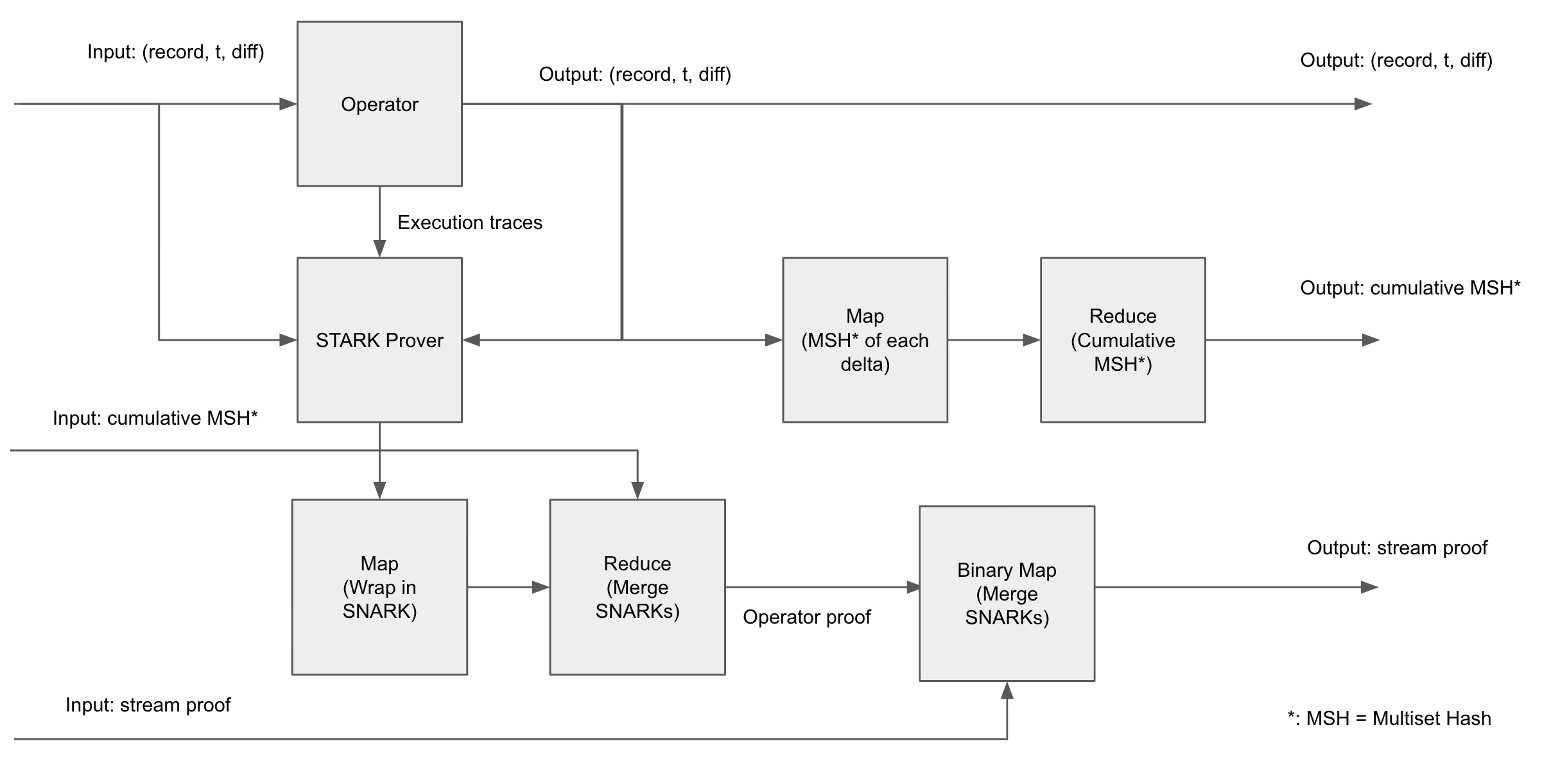
Non-Unary Operator Implementation
Operators with different numbers of inputs and/or outputs are implemented the same way, simply duplicating the relevant parts.
Firstly, we generate one STARK proof for the emission of all outputs given all inputs. Then we simply have multiple recursive accumulation pipelines running in parallel, one for each output maru stream. In each of those pipelines, we have a sequence of "binary map" operators that merge the cumulative operator proofs with the previous operator's cumulative stream proofs, one for each input stream.
Economics
In order for Maru to accrue value, it needs a token, and that token should provide a simple way for developers to pay for computation within Maru. In this chapter we will describe our solution to this.
Design Goals
Maru's economics design is informed by observing the failures and successes of other models that came before us. In synthesis, we make the following design goals:
- Consistent, budgetable pricing
- Composition strongly incentivized
- Zero infrastructure overhead for developers
- Incentive for investors to hold MARU and participate in the network
To these ends, we take the following high-level approaches:
- Charge for computation, not data
- Gas metered by number of STARK trace rows
- Gas fee allocation based on dataflow topology
Charge for computation, not data
Charging for data - that is, charging per "query" of certain data is hard for several reasons. Firstly, queries are too difficult to price based on relative complexity and size of the data since, before they are executed, it's quite difficult to know how many resources will be consumed. This essentially pushes all pricing onto end-consumers. This leads to highly volatile prices, which are hard to budget for a runway-conscious developer. Even worse, this requires the end-user to pay on-demand for each query, requiring them to have GRT and sign a microtransaction for every query is egregiously bad UX. This, in turn, requires developers to set up a relayer to pay for the user's queries, and that relayer needs sybil-prevention. This pushes a lot of infrastructure costs onto the developer, increasing the cost in engineering-hours of adopting such a solution.
In a streaming context, there's also another problem - since all "queries" are defined at compile-time, the result of each "query" is the same once it's emitted from a stream. Thus there's nothing stopping parties from buying it once and "pirating" it to their peers, effectively reducing "query fees" to zero.
We avoid all of these problems by charging for computation instead of data. In other words, we meter fees based on the computational complexity of the operator(s) that produce a stream of data. Another way to look at it is to see it as "paying for the production of data" instead of data itself.
Gas Metering
If we charge for computation, we need a way of "metering" computation. In a decentralized system, this requires the network to "decide" how much gas a computation consumed. Blockchains do this via consensus, which we explicitly avoid in Maru. The other way to do it is to prove it. Conveniently for Maru, each STARK proof takes the number of trace rows as a public input, so we get a "proof" of the number of trace rows in a computation for free. The remaining question is the following: Is this a good metric for the computational cost of an operator?
The answer is yes. Why? Because proving cost dominates execution cost. And since every delta for every operator is run through an instance of our runtime, and the STARK prover cost scales directly with the number of trace rows of a given runtime instance, the total number of trace rows provides a very solid metric for the cost of computation.
It's totally OK that this ignores the cost of SNARK recursion because the number of recursive SNARK proofs to be generated is proportional to the number of STARK proofs to be accumulated. In other words, the SNARK prover cost is determined by the STARK prover cost, and trace rows directly measure the STARK prover cost.
Thus we define 1 unit of gas to be equal to 1 STARK trace row.
Gas Tank
So now we have a way to meter gas. But two questions still remain:
- How is each unit of gas priced?
- How are fees paid?
Since we prioritize price consistency, we have a very simple answer to the first question - 1 unit of gas is priced at 1 yoctoMARU. The tradeoff here made obvious by Solana is the lack of a fee market means the network must be highly spam-resistant and the supply of computation must always be able to fulfill its demand. Maru doesn't have a problem with the former because all of our source streams solve this problem for us - if we pull data from a blockchain, a blockchain will either halt or increase its gas fees, the latter of which is indistinguishable from normal operation from Maru's viewpoint. The latter should be easy-ish to deal with, as demand for computation only increases when new operators or source streams are added, neither of which can cause drastic spikes.
To avoid infrastructure costs and reduce complexity for developers, we use a "gas tank" model to answer the second question. Each operator has a balance of MARU attached to it that serves as its "gas tank". Then, when fees need to be paid, they are deducted directly from the operator's gas tank. If the operator's balance is insufficient to pay the fees, the operator is removed the dataflow, which in will block all downstream operators. Since this event would be catastrophic for any application, network participants are strongly incentivized to ensure there is enough MARU in the operator's account. Since prices are predictable, this should be easy to automate.
Gas Futures Market
As a way for passive token holders to participate in the network, we introduce a "gas futures market". This serves the following functions:
- Allow developers to have not just consistent, but fixed prices in any currency (USDC, ETH, etc).
- Provide yield to token holders who provide gas liquidity
A "gas future" is defined as the following:
- The seller (developer) agrees to pay the buyer (token holder) a fixed amount of a specific token (USDC, ETH, etc) each epoch
- The buyer (token holder) agrees to place a fixed amount of MARU into a specific operator's gas tank each epoch.
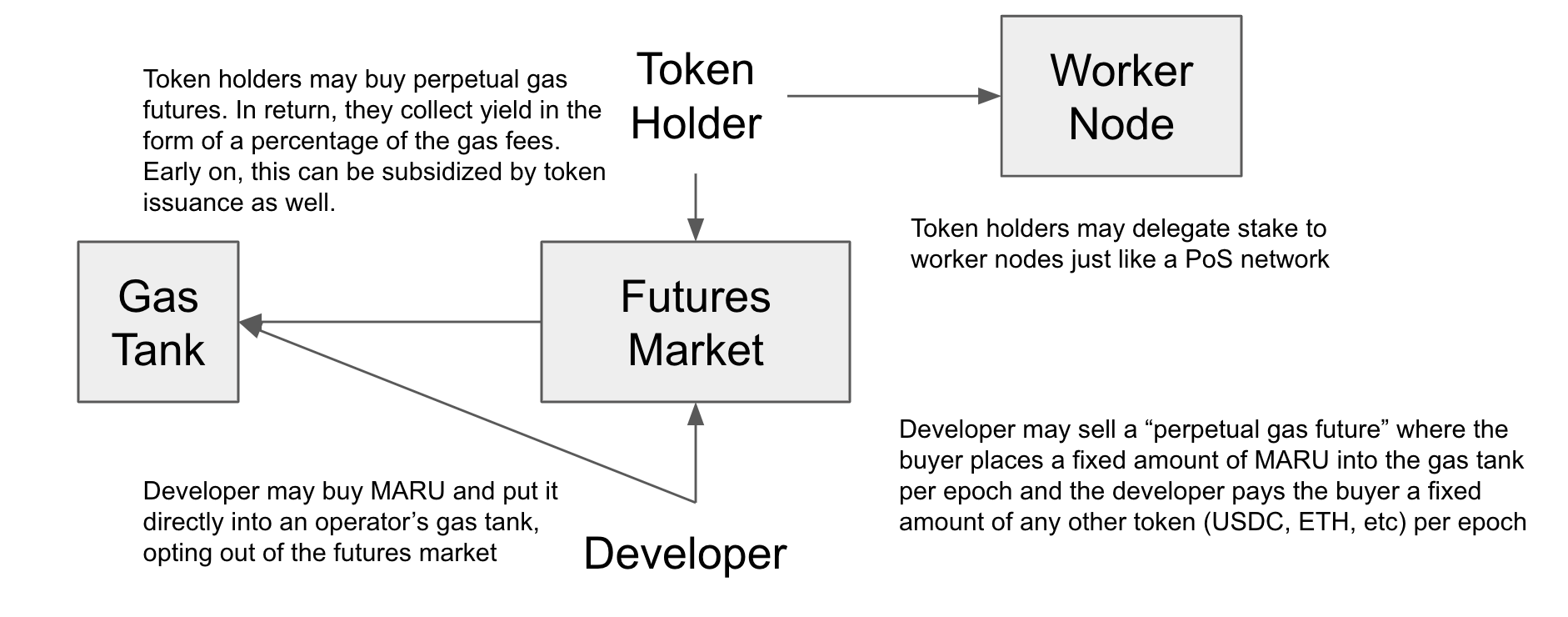
It seems like there are two potential problems with the futures market. Firstly, each operator has its own futures market, fragmenting liquidity. Secondly, investors who buy such a future from developers are betting against, not in favor of the price of Maru relative to the token chosen by the developer. However, we can assume there will inevitably be a secondary market, and a secondary market addresses both problems. It addresses the first problem by providing a way to trade futures on different operators, allowing liquidity to freely shift between operators. It addresses the second problem because a secondary market will inevitably allow traders to short-sell their gas futures.
Gas Payment
That leaves the third question, to which our answer is slightly more complicated. We split the protocol into "epochs", which are roughly 10 minutes long. Each epoch, the following occurs:
- The total number of trace rows consumed by each operator is calculated and proven. This is the amount of gas that has to be paid for each operator.
- The corresponding amount of yoctoMARU is deducted from each operator's account into a "rebate pool".
- K% of the rebate pool is distributed to the holders of gas futures (see next section)
- The rebate pool is distributed evenly across all worker nodes
Since workers are paid the same regardless of which operator they run, and operators may vary in terms of proving cost, it is important that operators are assigned to workers in a random-ish, unbiasable manner so that on average they earn a roughly equal income. In the hosted testnet, this will be trivial. Doing this in a decentralized manner is an open problem to which we have several avenues outlined in open problems.
Potential Drawbacks
Since the operator trace counts are proven, it's impossible for nodes to lie about how many trace rows they produced without being detected. If they do so anyways, they will get slashed. This eliminates the possibility for a wide variety of attacks involving lying about the amount gas consumed.
One potential issue with this protocol is that the amount of fees workers collect is proportional to the number of trace rows. That means workers potentially have the incentive to add extra useless trace rows to their STARK proofs to earn more fees. This can manifest in two ways - firstly by the prover submitting their own, less-efficient operator implementations to the dataflow, and secondly by inserting extra padding rows in each Aincrad execution trace. Since padding rows are the only legal row that does nothing, this is the only way a worker node could carry out this "attack".
The former is mitigated by market forces - developers will always prefer to pay for the more-efficient version. The second can be mitigated with a slight addition to the Aincrad STARK. We can add a new public input num_useful_rows, which is the total number of trace rows minus padding rows. Then the STARK can check this against the end of the program's execution, which the prover can't manipulate because the hash of the program's bytecode is included in the STARK. Then, in addition to verifying the proof, the verifier can check that the final trace length is the smallest power of two greater than or equal to num_useful_rows. This allows the verifier to detect when the trace is longer than it should be.
It's also prossible to do this by adding redundancy r to the operator assignments and comparing the trace length of each of the r STARK proofs, but this requires adding complexity to the process by which STARK proofs are submitted and it also duplicates work.
Benefits
- It's easy for any honest node that meets the minimum stake requirement to be profitable as long as there is enough demand in the network. If there is not enough demand, then it will no longer be profitable, so the number of nodes will scale down until it is profitable. This acts as a sort of "market-driven auto-scaling".
- There is a strong incentive for the developer community to come together and co-optimize their infrastructure, factoring out common sub-components and sharing the gas costs.
- Investors have a strong reason to hold MARU, since they can earn yield by proving gas liquidity through the futures market.
- Developers need no additional infarstructure to use Maru - no relayers to pay query fees and no authentication services to protect those relayers from spam.
- Developers have consistent prices, potentially fixed prices if they so wish.
- Developers don't need to hold MARU to use Maru.
Domain Specific Language
Note: none of this is actually implemented yet. The purpose of this page is, at the moment, to demonstrate how we anticipicate developers will (eventually) use Maru once it becomes a general computational platform. Most, if not all of this will likely change in the future.
Maru developers will be able to program their operators with Jutsu (name tentative), our DSL. Jutsu compiles down to a set of STARK-VM binaries (one for each operator) and a description file that specifies their inputs, how to chain them together, and how to graft them onto the existing dataflow graph. These bytecodes and description files will then be uploaded to an "operator registry", from which the protocol will update its view of the dataflow and execute it.
Here's some examples of how we expect Jutsu programs to look:
Unary map
Let's say the user wanted to write an operator that takes a collection of ratios expressed as 64-bit fixed-point decimal numbers (expressed as u64s) and turn them into percentages. They can define a function and then use the map operator to convert the prices.
// They might write it like this
fn to_pct(ratios: u64): u64 {
return ratios * 100
}
// or like this
fn to_pct = (ratios: u64) => ratios * 100
Binary map
Let's say the user wanted to write an operator that takes a collection of NFT prices in wei and convert them to USDC given the current exchange rate (a single-element collection). They can "merge" the two collections into a single collection of tuples using the zip operator. Depending on what the two streams in question are, zip may be implemented differently under the hood by the compiler. In this case, the zip can be elided away completely and pushed as an input directly into the underlying VM of the map operator.
// They might write it like this:
fn nft_price_to_eth((meta, price): (NFTMeta, u256), exchange_rate: u256): u256 {
let converted_price = price * exchange_rate;
(meta, converted_price)
}
// or like this
fn nft_price_to_eth((meta, price): (NFTMeta, u256), exchange_rate: u256): u256 => (meta, price * exchange_rate)
// then, they can build the dataflow and `export` the output collection:
export collection nfts_priced_in_eth = @input("PRICE_STREAM_ID")
.zip("EXCHANGE_RATE_STREAM_ID")
.map(nft_price_to_eth)
Filter for all of the prices for ETH-USDC swaps on Uniswap
Let's say the user wanted to write an operator that produces a collection of prices for every ETH-USDC swap on Uniswap given a collection of every Ethereum log ever. They can do this using the filter operator.
const USDC_ETH_SWAP_LOG_SIGNATURE = "CONTRACT_LOG_SIGNATURE"
export collection filtered_logs = @input("ETHEREUM_LOGS")
.filter(log => log.contract_address == USDC_ETH_SWAP_LOG_SIGNATURE)
export collection prices = filtered_logs.map(log => log.price)
Compute a 24-hour block-by-block moving average of the ETH-USDC pair on Uniswap
Let's say the user wants to compute a 24-hour (~7200 Blocks) moving average over the ETH-USDC pair on uniswap. They can do this with the following steps:
- use the ETH-USDC swap logs from the previous example as input
mapthe logs to(block_number, price)tuples- in parallel, do the following:
- sum the prices for all of the swaps in each block
- count the number of swaps in each block
ziptwo the outputs of the previous step togethermapthe(sum, count)pairs to averages (i.e. divide them)- use an arrangement to index the averages by block number
- use a custom
moving_avgoperator that takes in an arrangement and computes an average over the "greatest" 7200window_lenelements of in the arrangement (i.e. the averages for the 7200 most recent blocks)
// Map logs to (block_number, price) tuples, clustered by block number
collection batched_logs = @input("ETH_USDC_SWAP_LOGS")
.map(log => (log.block_number, log.price))
.batch_by_key()
collection volumes = batched_logs.sum_by_key()
collection counts = batched_logs.count_by_key()
// Arrange averages by block number
arrangement block_averages = volumes
.zip(counts)
.map(((block_num, volume), (_, count)) => (block_num, volume / count))
.arrange_by_key()
.consolidate()
export collection moving_avg_24hr = block_averages.moving_avg(7200)
export collection moving_avg_1hr = block_averages.moving_avg(300)
operator moving_avg<T: Div<T> + Add<T>>(window_len: usize) {
input arranged items: T
output single current_window = arranged_items
.iter_descending()
.take(window_len)
.map(block_avg => block_avg / window_len)
.sum()
}
The batch_by_key operator tells the compiler that the keys produced by the map function will be clustered in the stream underlying the collection. This allows it to choose a more efficient implementation for subsequent operators. In this case, all logs from the block will appear adjacent to each other in the stream since they're in the same block. The naive sum_by_key version will build an arrangement (expensive) - the batch_by_key version will use an iteration context instead, which is much cheaper here.
For the arrangement, the user needs to arrange the averages by block number. They can use the built-in arrange_by_key operator for that. Internally, it builds a merkle tree (not a multiset hash) of the deltas and orders them by key, allowing efficient "random access" over historical updates through membership proofs. Then we use the consolidate operator to tell the dataflow to always consolidate deltas for the same keys. This arrangement can be re-used by any number of operators - to demonstrate this, the user also computes a 1 hour (~300 block) moving average using the same arrangement.
Then they can define a custom moving_avg operator by dropping down to the lower-level differential interface, which requires them to specify three things: input declarations, output declarations, and the logic itself. The logic is expressed the same way you'd define the program itself - conceptually this can be thought of a sort of "sub-dataflow". In the moving_avg operator, the user specifies that the items input is an arranged collection using the arranged keyword. Arranged collections allow the operator to perform key-value lookups and iterate over the collection's values. The single keyword on the output declaration signifies that the output is a collection that should always contain a single element. This is syntactic sugar for saying that each input delta should result in "removing the old window and adding the new window". The operator also uses a generic type parameter, signifying that it can build windows over any arranged collection of elements of any type T such that division and addition are well-defined for T.
Compiler Optimizations
The Jutsu compiler could be smart enough to consolidate operators expressed semantically into significantly more efficient concrete implementations, given what information it has about them. For instance, in the implementation for moving_avg above, instead of writing
.fold(moving_avg, (moving_avg, block_avg) => moving_avg + block_avg / window_len)
we write
.map(block_avg => block_avg / window_len)
.sum()
While the programmer logically expressed more operators, the compiler can assume addition is commutative, so it can produce a differential operator that exploits this fact, avoiding the need to iterate altogether (subtract the quotient for the previous window's oldest value and add the quotient for the new one). In contrast, the compiler can't assume the function given to fold is commutative.
Arrangements
Open Problems
Replacing Timely Dataflow's Non-BFT Scheduler
The timely dataflow library currently relies on a 'decentralized' scheduling system whereby streams are partitioned evenly between worker nodes and each worker node processes the entire dataflow graph on its "shard" of the data. However, it operates under assumptions of typical distributed systems deployed in data centers. It is not suitable for adversarial environments where worker nodes can exhibit arbitrary byzantine failures. This is by far the biggest open problem Maru has. That said, at a high level, we've already given this a fair bit of thought (just not as much as we would have liked to), and we have the following partial solution, which is probably broken and needs more work:
- Every epoch, worker nodes that meet a minimum stake "commit" to participating via an on-chain smart contract. This smart contract counts the number of participating worker nodes
num_workers. - A random value
ris sampled from a randmness beacon. Each node downloads and verifiesr. - Every node syncs their view of the dataflow graph with an on-chain "operator registry" smart contract, which contains all of the dataflow operators and links to decentralized storage (e.g. arweave) from which to pull their definitions and bytecode.
- Each element of every stream is partitioned into
num_workersbuckets using a (non-cryptographic) hash function -bucket(x) = h(x || r) % num_workers. Redundancy can be added by assigning multiple shards to each worker by repeating the process with permuted versions of the hash (e.g.h(x || r || 0),h(x || r || 1), etc). - If a node receives deltas, and any of the deltas are assigned to a node other than itself, the sender is slashed and removed from the active set.
- When a node receives deltas in a particular stream, it updates its multiset hash for the stream.
- When a node receives an accumulated proof for a stream, it verifies it against the block hash(es) for whatever source chains are needed. If it's invalid, the sender of the proof gets slashed.
- Everything else is exactly the same as in timely dataflow.
This more or less is a way to securely and randomly re-shuffle data shards and/or allow nodes to join/leave during each epoch. This deals with nodes violating the stream partition assignments, nodes executing operators incorrectly, and nodes not sending the deltas they're supposed to (thanks to multiset hashes).
Note that this solution does not yet address data availability for intermediate streams.
TODO
Multiset Hashes (MSH)
Suppose we had an unordered set of possibly repeating elements, and we wanted to be able to efficiently update its hash without needing to keep the entire set around in memory. That's exactly what a multiset hash does.
Why a multiset hash, not a set hash? Two reasons - firstly, because when we're incrementally updating the hash, we can't know if the element we're adding already exists in the set if we only have the hash, so we instead consider the number of times the element appears in the set.
Secondly, we use them because collections in the Maru programming model are multisets. In particular, for "linear" operators that don't require an arrangement (e.g. map, filter, sum, count) we won't need to use merkle trees at all, which are quite expensive to verify and update in a SNARK/STARK.
A Multiset is a set of elements such that, for each element, we keep track of its "multiplicity" - that is, the number of times the element appears in the set. This is different from a set, because sets do not consider "duplicates" - adding an element to a set that already contains will not change . If was a multiset, it would change. For more background on multiset hashes, check out this awesome article by Lúcás Meier.
The Hash Function
In Maru, we use the following hash function from Clarke et.al:
Where arithmetic is done over a field in which the discrete log problem is hard and is a cryptographic hash function whose output is an element in the field, and denotes the multiplicity of in the multiset .
We can then incrementally update the hash with a (possibly single-element) set of new values to add as follows, without keeping the entirety of in memory:
An implementation of this function can be found at https://github.com/proxima-one/multiplicity.
There's just one problem with the hash function as it was introduced by Clarke et.al - it requires a really big field to be secure (~4000 bits), and that's way too big to put into a starky STARK or plonky2 SNARK, whose native field is only 64 bits.
Luckily we can do the same thing in an elliptic curve group instead of a field:
The only difference here is that is now a hash function which outputs a point on the elliptic curve, not the field. This allows us to use a much smaller elliptic curve representation, which should be cheaper in a starky STARK or plonky2 SNARK. Lúcás Meier wrote a concrete implementation of this version over the Ristretto curve.
The "Goldilocks Curve"
Since we're doing this in STARKs and SNARKs, we want to avoid non-native field arithmetic. Even though the elliptic curve representation is smaller, non-native field arithmetic is quite expensive. Luckily, Thomas Pornin found a curve whose base field is a degree-5 extension of goldilocks, the native field for both starky and plonky2. While this curve is technically called ecgfg5, we call it the "goldilocks curve" because its value to us is that it's base field is a native extension.
An implementation of the multiset hash using this curve will allow us to avoid non-native field arithmetic when performing multiset hashes, which will make our STARK/SNARK circuits much more efficient.
A safe-rust implementation of the curve can be found here - in practice we'll want to build atop plonky2's implementation of the quintic goldilocks extension instead since we'll be using it in circuits.
Plonky2
Plonky2 is a recursive proving system combining TurboPLONK arithmetization with a FRI-based polynomial commitment scheme.
TurboPLONK Arithmetization
The PLONK arithmetization uses a global permutation argument to wire local constraints together. TurboPLONK introduces custom gates to PLONK, allowing for arbitrary local constraints to be defined.
Trace
The Plonky2 trace can be thought of as a matrix , where each trace cell () is an element in the prime field , with .
Each row corresponds to the wires of one gate; and each column corresponds to a wire polynomial such that
where is a primitive root of unity in .
Custom gates
In Plonky2, custom gates are represented as constraints on wire polynomials . For instance, an addition gate
may be represented as the polynomial constraint
Note: Here, each variable is mapped to the wire polynomial; in general, however, any arbitrary mapping is possible.
Gates are toggled on and off by preprocessed "filter" polynomials . For instance, the filter should enforce only on relevant rows of the trace:
The filtered addition gate thus looks like
In practice, a filter can be a composite of multiple binary filters. Plonky2 automates the construction of filter expressions for its custom gates, optimizing for an arrangement that minimizes constraint degree [see Section 3.1.1 of the Plonky2 paper].
Permutation argument
[Parts of this section have been adapted from the halo2 book.]
PLONK's permutation argument sets up routes between wires: i.e., it can constrain the value of one wire to equal that of another. In the below example, is constrained to equal . We can write this as a permutation such that .
We will label each trace cell using a unique field element . Then, we can represent by a vector of polynomials such that .
Now, given our permutation represented by over routed wires , we want to ensure that this "grand product" evaluates to 1:
where are random challenges.
Checking this "grand product" reduces to checking relations between coefficients of polynomials at "neighboring monomials". To see this, define a "running product" polynomial such that , and for
Then it is sufficient to enforce the constraints:
where when , and otherwise.
Note: To handle a large number of routed wires, Plonky2 splits the permutation product constraint into cumulative products [see Section 3.3 of the Plonky2 paper].
Combining constraints
The final polynomial that goes into FRI is a linearised form of a composite of the circuit's constraints. (See the Protocol section for details.)
The prover constructs the composite polynomial from the wire commitments, permutation product commitments, and vanishing argument commitments, and evaluates it at a verifier challenge point to get a claimed evaluation .
The that goes into the FRI protocol is a linearized version of the composite :
Notice that is a polynomial if and only if ; in other words, if , then is not a polynomial and will fail the FRI protocol.
FRI-based polynomial commitment
FRI is an efficient protocol for proving proximity to a low-degree polynomial. It proceeds in two phases: and . Plonky2 further includes a proof-of-work phase.
The prover has a function , where is a finite field, and the evaluation domain is a coset of a group contained in .
Note: The size of the evaluation domain is much larger than the degree . More precisely, , where is the Reed-Solomon code rate.
The prover claims that is an evaluation of a polynomial . In other words, they claim that
COMMIT phase
To commit to , the prover begins by expressing it as a linear combination of two functions, each purportedly corresponding to a degree polynomial:
Here, and correspond to the even and odd coefficients of , i.e. The intuition here is similar to that behind the arity-2 FFT (Fast Fourier Transform). This algorithm can be generalised to other arities.
Suppose now that is far from the degree- polynomial. This means that a significant fraction of queries on will not yield points on . The proximity gap result implies that, with high probability, any linear combination of and will be equally far from a degree- polynomial.
The prover now sends the verifier a commitment to . Next, Plonky2 instantiates as the root of a Merkle tree whose leafs are the evaluations of , and whose hash function is Poseidon in a sponge. Using , the verifier derives a random challenge . This is then used to construct a random linear combination of and :
Observe that our new function is half the degree: .
Further, we can halve the size of our evaluation domain through a clever choice of . We choose to be a finite field, such that For a function on , the symmetry means that half of the output values will be superfluous. In other words, we need only evaluate over half the domain:
where .
At each round in the phase, the verifier sends the prover a new random challenge . Then the prover uses it to make a new function and merkle commitment , halving the degree and evaluation domain size of the previous round's . Finally, at rounds, we are left with the constant function (degree 0) .
PoW phase
TODO
QUERY phase
The phase consists of rounds. In each round, the verifier makes oracle queries to read the prover's 's in select locations.
Protocol
FRI-based recursion
The recursive verifier circuit is a subcircuit encoding the constraints needed to verify a FRI proof. About 75% of the recursive circuit is taken up by verifying Merkle proofs, i.e. Poseidon hashes.
The diagram below shows how the FRI proof of one instance can be submitted to a later recursive verifier as part of the next instance:
Starky
Starky shares Plonky2's FRI-based polynomial commitment scheme, but replaces TurboPLONK with the Algebraic Intermediate Representation (), an arithmetization used in STARKs. is optimized for traces with repeating structure, where the same state transition function applies on all states in the trace. Here, each row in the matrix corresponds to a single state in the execution trace; and each column corresponds to a register.
The arithmetization is a special case of TurboPLONK arithmetization. This note explains their relationship in more detail.
Starky expresses the constraints of the computation using the following types of constraints:
-
Boundary constraints: these are applicable on only the first and last rows, and are often used to load the expected inputs and outputs of the computation. As in Plonky2, these are specified using preprocessed filters: where only evaluates to on the first row, and only on the last.
-
Transition constraints: these define a valid transition from the current state to the next state of the execution trace. These are valid on all rows except the last.
-
Constraints that are valid on all rows.
Starky additionally allows for permutations between pairs of columns.
Use Cases
This section highlights several potential use cases of Maru and provides high-level outlines of how they can be implemented.
Lifting Expensive Computation Off-Chain
There are lots of things that applications want to do on-chain because they require the security of L1, but they simply can't because they require too much data or are too computationally intensive.
With Maru, they can "lift" their computation off-chain, do it there, and then "settle" it back on-chain, where they can use the result however they see fit. Whatever the computation, it would look something like this:
- Pull in raw log / tx / state streams from every chain whose data we wish to incorporate in our computation if they haven't already been added to Maru.
- Write operators that filter for just the input data to our computation
- Write operators that perform the computation
- Subscribe to the output in one of the following ways:
- Subscribe from an off-chain service (API, Browser, etc) and use them there
- Build a merklized index (by address) of the result, and publish this merklized index to cheap, decentralized storage (e.g. Arweave or Filecoin). Browser clients and APIs can then interactively query the index.
- Settle the result and proof to a smart contract on any chain whose applications wish to use it. In the case we use data from chains other than the one consuming it, this constitutes a bridge, which comes with extra trust assumptions discussed in the bridge use case (which is the case for (almost) any bridge).
Here are some specific examples:
Credit Scores
Many companies want to build on-chain credit scores for the following reasons:
- Lending on chain is currently over-collateralized. Allowing under-collateralized lending would be a massive capital unlock for DeFi, and that requires the ability to "predict" or "quantify" risk of default.
- Lots of projects (DAOs, social networks, stuff involving the "real world", etc) are investing in building reputation / "trust" scores for users. But it turns out that credit scores can be used as reputation scores as follows:
- Instead of using reputation scores directly, use bonded stake.
- Allow users to borrow from an undercollateralized lending market to pay for that stake. The higher their credit score, the lower their collateral ratio, and the closer to "free" their stake becomes.
While there's a lot of research going into the credit scores themselves, there's another problem that will arise - the sheer amount of data needed to scalably calculate the scores. Robust scores will likely require data from several ecosystems and may be resource-intensive to compute. Performing this computation on-chain is infeasible, but taking it off-chain into a "SaaS Product" presents a massive trust problem not unlike the credit rating agencies we use today. If we care about making scores transparent and replacing the trust we place on credit rating agencies today with cryptography, it's important to be able to prove that scores are correct.
Companies that would be interested in this include:
- Lending Markets (Aave, Compound, Teller, etc)
- Social Networks (Mirror, Lens Protocol, etc)
- DAOs / Contribution Tracking (Gitcoin, Sourcecred, etc)
Off-Chain Pricing of On-Chain Assets
Bonds and Options are difficult to price on-chain, because efficient price formulas (e.g. Black-Scholes) are too computationally expensive and require too much data to perform on-chain. Being able to use better pricing strategies with the same security as L1 presents a large capital efficiency improvement without losing security.
Companies that would be interested in this include:
- Bonds Markets (Element Finance)
- Options Markets (Ribbon Finance, Synthetix, Zeta Markets, etc)
Social Graph Database
Aggregation and indexing are key features of social networks. Aggregation is necessary for tracking global interactions such as likes and follows; and indexing is needed to construct feeds, run search queries, manage spam, and otherwise interpret the social graph database. Since we cannot remove these centralized roles, the next best thing is to ensure that anyone can perform them with algorithmic transparency. In other words, any node should be able to verifiably contribute to a function: resume execution at the last checkpoint, perform an operation, and produce a proof of the operation.
Self-authenticating data provides a scalability advantage by enabling store-and-forward caches. Aggregators in a self-authenticating network can host data on behalf of smaller providers without reducing trust in the data's authenticity. With verifiable computation, these aggregators will even be able to produce computed views – metrics, follow graphs, search indexes, and more – while still preserving the trustworthiness of the data. This topological flexibility is key for creating global views of activity from many different origins.
source: Bluesky blog
User data stores
In a decentralized social network, users can host their databases on their own infrastructure. This forms a federated network of servers hosting user information, where no ordering is assumed between the data stores.
Each data store is identified by some keypair. This can be used to sign the data store root on each mutation, in order to prove the authenticity of the update.
Use-case: Aggregated "follow" relations
It would be valuable to construct a social-graph database of “follow” relations between users' data stores. This database is a secondary index; the user data stores are the primary/canonical store. Our aggregator will watch some set of user data stores for changes to their follows, and then update its secondary index.
Indexer for queries
A few useful queries (reads) to include are:
#![allow(unused)] fn main() { - isFollowing(from: DatastoreID, to: DatastoreID) -> boolean - listFollowers(to: DatastoreID) -> DatastoreID[] - listFollows(from: DatastoreID) -> DatastoreID[] - countFollowers(to: DatastoreID) -> number - countFollows(from: DatastoreID) -> number }
To handle queries, we construct an indexer. Frank McSherry describes how to translate these queries into operators for differential dataflow in a graph database here. The aggregator includes a proof for each operator used in the query.
Provable mutations
In response to updates in the user data stores, the aggregator must mutate its secondary database to match:
#![allow(unused)] fn main() { - addFollow(from: DatastoreID, to: DatastoreID, prf: Proof) - removeFollow(from: DatastoreID, to: DatastoreID, prf: Proof) }
Just like performing queries, we can write operators to react to these updates and include a proof for each operator. Additionally, the aggregator includes a proof of authenticity of the update (i.e. that it was signed by the data store's keypair).
Recursive proofs
The aggregator produces a proof for each operator. As the number of queries and mutations grows, the number of operator proofs quickly becomes too large for a client to verify. To reduce the number of proofs, we use the proof pipeline to prove them all in parallel and merge all of the proofs together.
Indexer
This document outlines how Maru can be used to build a fully-verifiable indexer.
Overview
Maru can be viewed as having three major "components":
- Ingress - pulling external data streams into Maru
- Dataflow - a graph of operators, each of which takes one or more streams as input and produces one or more streams as output
- Egress - external consumers (applications, relayers, etc) subscribe to the outputs of the operators they are interested in.
To build an indexer, we split the process into two parts:
- Index-Construction Operator - We can express the construction of an index as a Maru operator that takes in a stream of deltas and outputs a collection of
(hash, node_kind, key, value, left_child_hash, right_child_hash)tuples corresponding to a merkle index of the input stream's data, consolidating deltas as they come in. - Query Service: Then subscribe to this operator's output from an external service which, in turn, provides an API through which clients may interactively query this index.
This means that the only queries users may dynamically perform at run-time are, in SQL-speak, SELECT WHERE statements - developers can't simply point their webapps at a magic API and ask for any query they want if they never defined it up-front.
That said, defining the expensive queries up-front doesn't end up being a blocker for applications. The only difference is developers have to specify their more complex queries up-front - to get any sort of performance, developers typically have to do this anyways, and proper tooling can smooth over any difference in developer experience.
Index-Construction Operator
This operator is more or less an "export" of an arrangement. That is, the output is simply a stream of updates to the arrangement. While arrangements can be expensive, they only need to be done once for any stream, and they're updated incrementally. Furthermore, many operators (join, group_by, etc) require the usage of an arrangement anyways, so in the case the index's search key is the same as the one used in the arrangement, this operator is virtually free. In any case, the same index is used across every application, and every down-stream query service (second component) as well - the cost to update it only needs to be performed once.
Arrangements are sharded, indexed representations of a stream of deltas. In Maru, arrangements are sharded Merkle trees that are constructed from a stream according to a particular search key, and each tree comes with a proof linking the Merkle root of the indexed stream with the stream's running multiset hash. See the page on arrangements for more information.
In the general case where we don't already have an arrangement of the stream by the search key we want, it will look something like this:
- use a
mapeach recordRin the input collection (abstraction of a stream) to a tuple(K, R)according to a custom key functionfwhich defines the search key. - create an arrangement of the stream by-key (the first element of the tuple).
- flatten every batch of updates to the arrangement to a stream of merkle tree node additions and removals.
Query Service
The query service subscribes to the index-construction operator(s) and provides a verifiable interface for querying the merkle indices. This can manifest in a myriad of ways, each with different tradeoffs. These are the two we've considered so far:
- A centralized API that keeps the Merkle tree nodes in a key-value store and provides a REST-API for querying values. Upon request, the API responds with a merkle proof for the query (be it a membership, non-membership, or range query) and the fully-accumulated SNARK proof that the merkle root is correct. Presumably the client has its own RPC node with which it can check whether or not the given block hash is in the canonical chain(s) for the data from which the input was pulled.
- In principle, this could be decentralized with its own protocol for discovering indexed streams to serve and balancing bandwidth costs across the network via its own tokenomics. If MARU were used here, that would present a significant additional value capture mechanism for Maru.
- Snapshot the Merkle node collection periodically, dump its contents into a flat file, and publish it in some cheap, immutable file store (Arweave, S3, IPFS, Filecoin, etc)