Introduction
Before diving into the details of Maru, let's first get an idea of the kind of problem Maru tries to solve.
The problem Maru solves
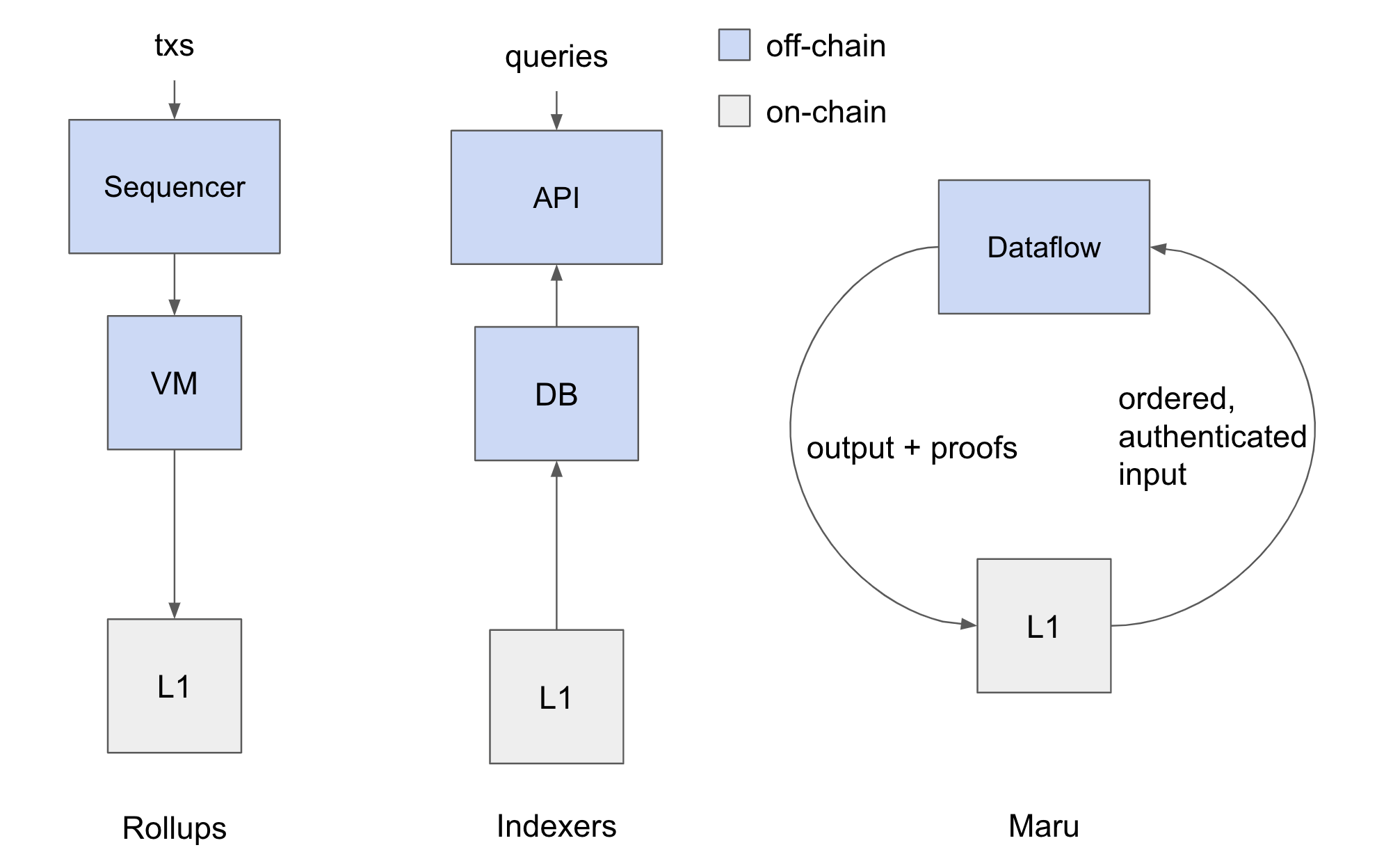
Blockchains are highly resource-constrained environments, so there are large inherent constraints on what developers can do on-chain. Thus, people have developed infrastructure that does stuff off-chain, but in a manner with security guarantees as close to those of L1 as possible:
- Rollups, which take off-chain data, "sequence" it into batches of transactions, execute them to produce state deltas, and periodically settle those state deltas in batches. This allows them to execute many more transactions than L1 can. There are two kinds of rollups:
- Optimistic rollups (OR) have to be "re-executable" on L1, so you can't perform a computation in an OR that's infeasible to perform on L1. By "infeasible", we mean actually infeasible (e.g. uses above max gas or different programming model incompatible with that of the L1) - "expensive" operations that are feasible to perform on L1 are ok.
- ZK Rollups (ZKR) don't have to be "re-executable" on L1 - they are free to use whatever programming model, so long as the proof is cheap enough to verify periodically on L1. Almost every ZKR in production today is focused only on payments, not "general" computation. That said, we're beginning to see "general" ZKRs come online (e.g StarkNet).
- Indexers, which take on-chain data, perform some computation to get the data into a queryable form (i.e. an index), and make that index available to code that exists off-chain (e.g. webapps, backend APIs, etc). Building indexes requires scanning over massive amounts of data, which is not feasible on-chain.
- Oracles, which take off-chain data, "verify" it against the source, and settle "on-chain" after the verification process. This allows people to query data from REST APIs and settle it on-chain.
While each of the solutions differ in trust assumptions and how much security they retain from L1, they share one common goal - do as much work as possible off-chain while retaining as much security as possible. In doing so, however, they lose a crucial property that exists on-chain - secure composability. Off-chain indices secured by "fishermen" and "optimistic challenge periods" are not composable. A smart contract on one rollup can't call a smart contract on another rollup without a state bridge. One oracle secured by a "multisig" can't be fed into another without a loss of security or stronger trust assumptions at every step of composition (does the smart contract need to verify the multisig for every oracle? Is it sufficient to do so only at the end? etc).
This is a problem if we want to actually build a "new web". The reason "web2" was so successful was because people could stitch APIs together into complex applications, but, at the moment, the only secure composability we have is in smart contracts. This is what Maru provides in a most general sense - scalable, secure, and composabile off-chain infrastructure.
| solution | functionality | finality / data consistency | security | scalability | composability |
|---|---|---|---|---|---|
| oracles | 'verify' off-chain data and make it queryable on-chain | strong (trust oracle provider to provide consistent data) | multisig | depends | introduces stronger trust assumptions at each layer |
| indexers | index on-chain data and make it queryable off-chain | weak (must wait for fishermen to resolve challenges) | fraud proof | depends | indices can't build atop other indices |
| optimistic rollup | do expensive stuff off-chain and batch-settle to L1 | weak (must wait for challenge period) | fraud proof | rollup txs must fit in L1 gas limit | cannot compose proof instances |
| zkVM rollup | do expensive stuff off-chain and batch-settle to L1 | strong (immediate finality on L1) | ZKP | sequential execution - O(N) recursive proofs - O(1) | cannot compose proof instances |
| Maru | all of the above | strong (immediate finality on L1) | ZKP | parallel execution - O(1) recursive proofs - O(1) | stream operators fully composable and only need to be executed/proven once |
How Maru solves that problem
It's become quite clear that L1s are best used for data availability and verification, and that everything else should happen off-chain - it's a place we settle data. Rollups and Oracles package off-chain data and post it on-chain. Indexers package on-chain data and post it off-chain. Maru completes the circle - it packages on-chain data, processes it off-chain, packages that off-chain data, and posts it back on-chain.
How? Using ZKPs. A ZKP allows us to prove "computational integrity" (CI) - that is, prove that, given an input A and a program P, a claimed output B is, in fact, the correct output of P when you give it A as input. In other words, if we trust the input, we can trust the output. We trust the consensus of L1s, and therefore we trust the input. The block hash is a digest of all data in the blockchain, and we can use it to build a succinct proof of CI - all we need to verify it is the current block hash, no matter how big the input is. And if we settle the proof on the same blockchain we took the input from, we have the block hash, and we can post the output data only if the proof verification succeeds. Or, we can settle the proof on a different blockchain, in which case Maru acts like a bridge (though with some extra trust assumptions).
However, we're not limited to a single program. If program P1 takes as input A and outputs B, and P2 takes as input B and outputs C, we can make CI proofs for P1 (A -> B) and P2 (B -> C). Then we can "merge" the two proofs together and make a single proof for both (A -> C) via a "recursive proof". Since we have a proof for each step, there's no loss in security from one step of composition to the next, unlike a "multisig" or "optimistic challenge period". And Maru is designed to do this at massive scale without consensus.
It's also worth mentioning that Maru can pull data from any ordered, authenticated source. It's not limited to blockchains - it can be an oracle, a signed data feed from a 'trustworthy' organization, or something else. Each data source will come with different trust assumptions, and it's ultimately up to the developer to evaluate them on a case-by-case basis.
How is this different from...
a 'general purpose' zkVM rollup?
A zkVM rollup must order (i.e. sequence) transactions on its own. Maru explicitly relies on the data source for that. Additionally, Maru's programming model (composable operators) allows parallel execution and composability without bridges. In contrast, while a zkVM rollup could give different applications their own VM, composability between those applications requires a 'bridge'. One can actually think of Maru as a parallel zkVM rollup where each "application domain" has separate state and the data dependency graph is specified at compile-time.
an indexer?
An indexer only builds indices - that is, they take data from chain, package it in a queryable form, and make it available. Maru is a general compute platform, not an indexer, though it could very well act as one.
an oracle?
An oracle only takes data from off-chain and posts it on-chain, whereas Maru also pulls data from off-chain and makes it usable on-chain. Oracles also can't "mix" off-chain data with on-chain data through computation before settling to L1 without complicated trust assumptions, while Maru can. That said, since Maru only requires data sources be "ordered" and "authenticated", Maru can use oracles as data sources, and Maru can pull from the same data sources that they do.